
Quartz在集群模式下通过故障切换和任务负载均衡来实现任务的高可用(HA High Available)。而集群模式是通过争用数据库悲观锁来实现必须使用JdbcStore持久化存储任务。这个可以先阅读之前集群管理文章Quartz管中窥豹之集群管理
故障切换
当其中一个节点在执行一个或多个作业期间失败时发生故障切换(Fail Over)。当节点出现故障时,其他节点会检测到该状况并识别数据库中在故障节点内正在进行的作业。任何标记为恢复的作业(在JobDetail上都具有"请求恢复(requests recovery)"属性)将被剩余的节点重新执行,已达到失效任务 转移。没有标记为恢复的作业将在下一次相关的Triggers触发时简单地被释放以执行。
1、每个节点Scheduler实例由集群管理线程ClusterManager周期性(配置文件中检测周期属性clusterCheckinInterval默认值是 15000 (即15 秒))定时检测CHECKIN数据库,遍历集群各兄弟节点的实例状态,检测集群各个兄弟节点的健康情况。
2、当集群中一个节点的Scheduler实例执行CHECKIN时,它会查看是否有其他节点的Scheduler实例在到达它们所预期的时间还未CHECKIN。若检测到有节点在预期时间未CHECKIN,则认为该节点故障。判断节点是否故障与节点Scheduler实例最后CHECKIN的时间有关,而判断条件:
LAST_CHECKIN_TIME + Max(检测周期,检测节点现在距上次最后CHECKIN的时间) + 7500ms < currentTime。
3、集群管理线程检测到故障节点,就会更新触发器状态,状态更新如下。
| 故障节点触发器更新前状态 | 更新后状态 |
| BLOCKED | WAITING |
| PAUSED_BLOCKED | PAUSED |
| ACQUIRED | WAITING |
| COMPLETE | 无,删除Trigger |
4、集群管理线程删除故障节点的实例状态(qrtz_scheduler_state表),即重置了所有故障节点触发任务一般。原先故障任务和正常任务一样就交由调度处理线程处理了。
代码参见
下图是集群管理线程CHECKIN时第一次CHECKIN或者发现故障节点后需获取实例状态访问行锁,才能更新触发器状态,删除故障节点实例状态等等。

下面两张图是查找故障节点时,会查找所有集群节点的实例状态,然后遍历判断是否故障。

查找集群状态语句

下图是根据节点实例最后CHECKIN时间判断是否节点故障的方法。

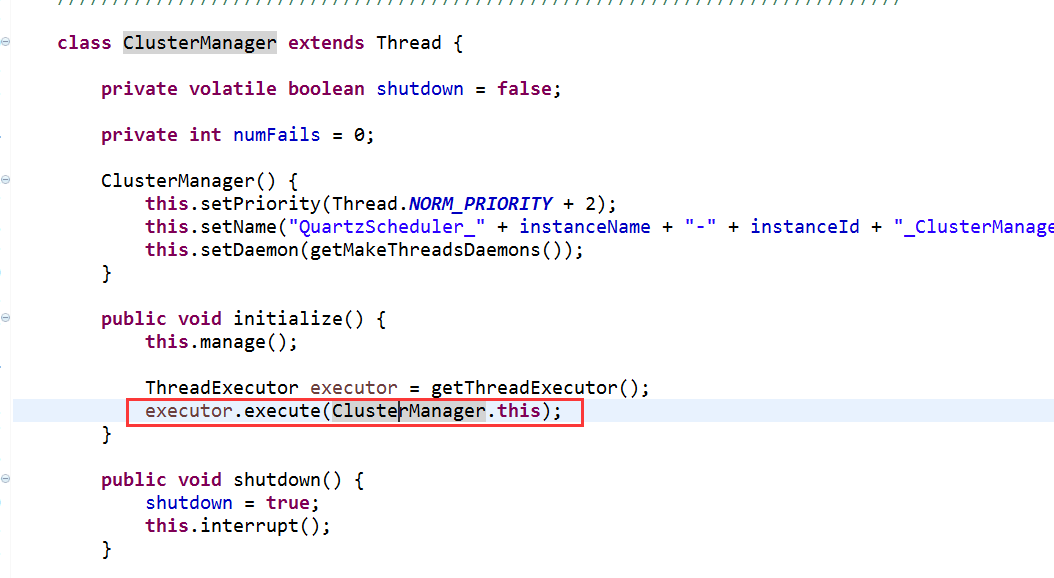
下图可知,集群管理线程是单独的线程实例。

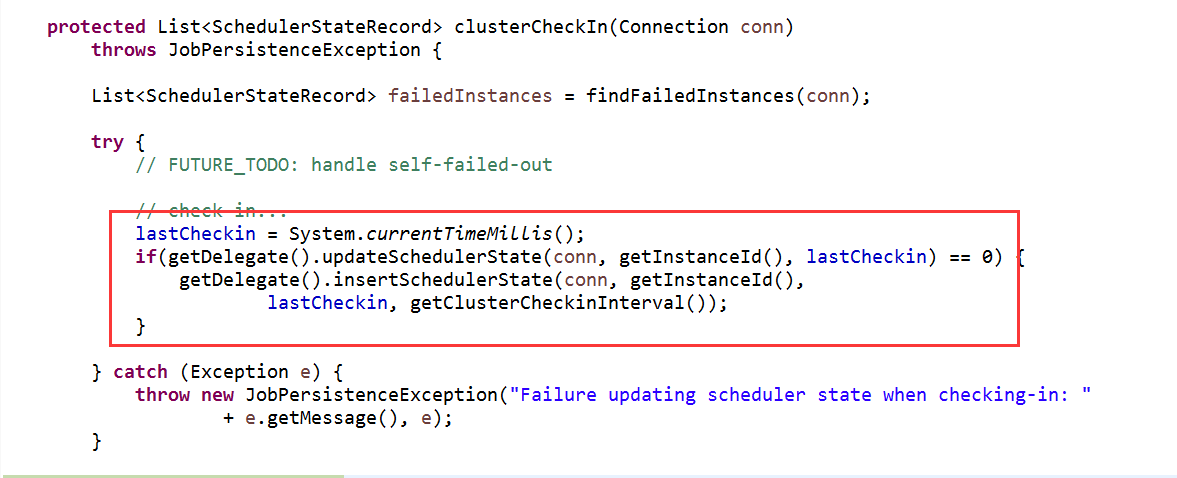
下图可知,集群管理线程检测完后要更新最后检测时间
负载均衡
负载平衡自动发生,群集的每个节点都尽可能快地触发Jobs。当Triggers的触发时间发生时,获取它的第一个节点(通过在其上放置一个锁定)是将触发它的节点。
它不一定是每次相同的节点 - 哪个节点运行它或多或少是随机的。负载平衡机制对于繁忙的调度器(大量的Triggers)是近似随机的,但是对于非忙(例如,很少的Triggers)调度器而言,有利于同一个节点下执行(Why?)。
集群下任务的调度存在一定的随机性,谁先拥有触发器行锁TRIGGER_ACCESS,谁就先可能触发任务。当某一个机子的调度线程拿到该锁(别的机子只能等待)时,
1、 acquireNextTriggers获取待触发队列,查询Trigger表的判断条件:
NEXT_FIRE_TIME < now + idleWaitTime + timeWindow and TRIGGER_STATE = 'WAITING'
然后更新触发器状态为ACQUIRE
2、触发待触发队列,修改 Trigger 表中的 NEXT_FIRE_TIME 字段,也就是下次触发时间,计算下次触发时间的方法与具体的触发器实现有关,如Cron表达式触发器,计算触发时间与Cron表达式有关。参见:
org.quartz.impl.triggers.CronTriggerImpl.triggered(Calendar)
触发待触发队列后及时释放触发器行锁。
3、这样,别的机子拿到该锁,也查询 Trigger 表,但是由于任务触发器的下次触发时间或者状态已经修改,所以不会被查找出来。这时拿到的任务就可能是别的触发任务。这样就实现了多个节点的应用在某一时刻对任务只进行一次调度。对于重复任务每次都不一定是相同的节点,它或多或少会随机节点运行它。
代码参见
如下面,如果是集群,则会开启基于数据库行锁的集群任务调度机制。
org.quartz.impl.jdbcjobstore.JobStoreSupport.initialize(ClassLoadHelper, SchedulerSignaler)

获取待触发队列的方法

集群功能最适合扩展长时间运行或cpu密集型作业(通过多个节点分配工作负载)。如果需要扩展以支持数千个短期运行(例如1秒)作业,则可以考虑通过使用多个不同的调度程序(包括HA的多个群集调度程序)对作业集进行分区。调度程序使用集群范围的锁,这种模式会在添加更多节点(超过三个节点 - 取决于数据库的功能等)时降低性能。
注意:
Never run clustering on separate machines, unless their clocks are synchronized using some form of time-sync service (daemon) that runs very regularly (the clocks must be within a second of each other). See http://www.boulder.nist.gov/timefreq/service/its.htm if you are unfamiliar with how to do this.
Never start (scheduler.start()) a non-clustered instance against the same set of database tables that any other instance is running (start()ed) against. You may get serious data corruption, and will definitely experience erratic behavior.
参考
Quartz教程 https://www.w3cschool.cn/quartz_doc/quartz_doc-2put2clm.html
调度系统入门和调度高可用实现方案 https://www.jianshu.com/p/810400e6a274Quartz
本文由 wenqy 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Nov 8,2020